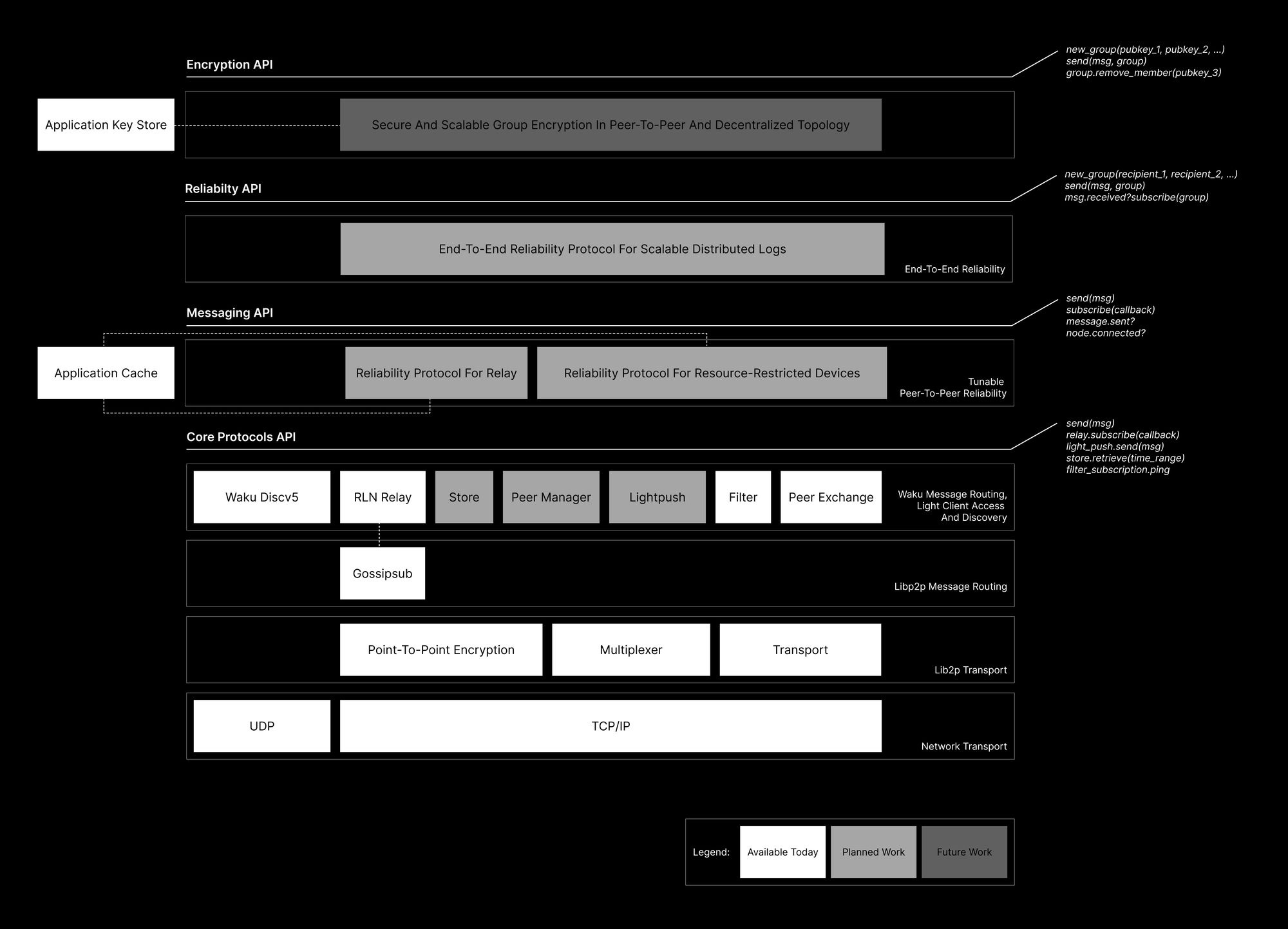
This post outlines an integration proposal for the “e2e reliability protocol” (proposed here) into the status-go codebase, specifically focusing on its implementation within the encryption layer. The goal is to achieve e2e reliability in the simplest and quickest way - albeit with tradeoffs as compared to an ideal approach such as pulling all encryption related stuff into an API (which primarily has implementation challenges and requires longer development timeframe). The idea is as follows:
- Reliability Library: We’ll create a new library that implements the core functions of our e2e reliability protocol. This library will operate on unencrypted application data, adding reliability metadata before encryption occurs.
- Message Wrapping: We’ll extend our message structure to include reliability information such as Lamport timestamps and causal history. This wrapping occurs before encryption, effectively extending the application protocol.
- Limited Caching: The library will maintain a short-term cache of recent message IDs, used for the rolling bloom filter, building causal history, and initial causal dependency checking. Fallback to longer-term history kept by the application could be used to increase the time period covered by reliability.
- Application Interaction: The library will provide methods for the application to interact with the reliability system, including marking causal dependencies as met and handling missing messages.
Reliability Manager
The ReliabilityManager will be the core of our new library, designed to work with application data and the reliability constructs.
Breakdown of Protocol Components
| Component | Functionality | Interaction with Application |
|---|---|---|
| Lamport Timestamp | Maintain and increment Lamport timestamps internally | Application provides clock value to initialize Lamport Timestamp |
| Causal History & Message ID Log | Maintain a unified log of recent message IDs (e.g., last 500) for acknowledged messages. The causal history of a message consists of the last few message IDs in this log. | Application provides long-term storage and retrieval for older messages |
| Bloom Filters | Maintain and update rolling bloom filter for recent message IDs | Application doesn’t need to interact with this |
| Message Buffering | Short-term buffering of incoming message IDs with unmet causal dependencies and outgoing unacknowledged message IDs | Application handles long-term storage and retrieval |
| Dependency Checking | Check dependencies against library’s recent message history | Return list of missing dependencies to application |
| Acknowledgment Tracking | Track acknowledgments for outgoing messages based on bloom filters and causal histories in received messages | Application marks messages as “sent” based on library signals |
Note: In the context of Status, for the initial implementation, we could use a single channelID per Community, matching the proposed content topic usage. This simplifies the implementation while allowing for potential future expansion to sub-channels if needed.
Message History Management
The reliability library will maintain a short-term storage of recent message IDs (last 500 messages) for efficiency. The application will handle extended history storage and retrieval.
API Description
Sending a Message
In Go:
func (rm *ReliabilityManager) WrapOutgoingMessage(message []byte, channelID string) ([]byte, error)
In C:
unsigned char* WrapOutgoingMessage(ReliabilityManager* rm, const unsigned char* message, size_t messageLen, const char* channelID, size_t* outLen);
- Library wraps the unencrypted message with reliability metadata (Lamport timestamp, short causal history)
- Library updates internal Lamport clock
- Library adds this message to an unacknowledged outgoing buffer to later ACK from an incoming message
- Later when the message is ACKed, it is removed from the outgoing buffer and the message ID is added to the log
- Returns wrapped message for application to encrypt and send
Receiving a Message
In Go:
func (rm *ReliabilityManager) UnwrapReceivedMessage(message []byte) ([]byte, []MessageID, error)
In C:
typedef struct {
unsigned char* message;
size_t messageLen;
MessageID* missingDeps;
size_t missingDepsCount;
} UnwrapResult;
UnwrapResult UnwrapReceivedMessage(ReliabilityManager* rm, const unsigned char* message, size_t messageLen);
- Library unwraps reliability metadata
- Library sweeps the outgoing buffer and marks messages as ACKed that match the causal dependencies and/or received bloom filter
- Checks causal dependencies against recent history
- If all dependencies met: returns unwrapped message and null for missing dependencies
- The message ID is then added to the message log and removed from the incoming buffer
- If dependencies not met: returns unwrapped message and list of missing MessageIDs
- Then the application will check if these missing dependencies exist in longer-term app history or retrieve them from a history store
Marking Dependencies as Met
In Go:
func (rm *ReliabilityManager) MarkDependenciesMet(messageIDs []MessageID) error
In C:
int MarkDependenciesMet(ReliabilityManager* rm, const MessageID* messageIDs, size_t count);
- The missing dependencies are reported as “missing” from the PoV of the library in its own short-term history and provided to the application.
- The application can try to find these in its own history or via a store query to a history store. It should use this method to mark these dependencies as met within the library to ensure the incoming buffer is appropriately maintained.
- Library updates its internal state and processes any buffered messages whose dependencies are now met
Signals
The library will emit the following signals:
- Message ready for processing
- Outgoing message marked as sent
- Periodic sync required
Go:
func (rm *ReliabilityManager) SetPeriodicSyncCallback(callback func())
Here are the C function pointer types for each signal:
// Signal for message ready for processing
typedef void (*MessageReadyCallback)(const char* messageID);
// Signal for outgoing message marked as sent
typedef void (*MessageSentCallback)(const char* messageID);
// Signal for periodic sync required
typedef void (*PeriodicSyncCallback)(void);
// Function to register callbacks
void RegisterCallbacks(ReliabilityManager* rm,
MessageReadyCallback messageReady,
MessageSentCallback messageSent,
PeriodicSyncCallback periodicSync);
The application can register these callbacks with the ReliabilityManager to handle the respective signals:
MessageReadyCallback: Called when a message’s causal dependencies have been met and it’s ready to be appended to the internal log…MessageSentCallback: Called when an outgoing message has been acknowledged as sent. At this point, the message ID is added to the message log and removed from the outgoing buffer.PeriodicSyncCallback: Called when the library suggests a synchronization should be performed. The application can decide when and how to act on this signal.
Integration with status-go
The proposed reliability system would integrate with status-go primarily through the encryption layer and message handling processes. Here’s an overview of how it would work within the status-go context:
Integration Points
The likely integration points would be:
- In
protocol/v1/status_message.go, particularly in theHandleTransportLayer,HandleEncryptionLayer, andHandleApplicationLayermethods. - In the encryption layer, possibly in
protocol/v1/status_message.gowithin theEncryptionLayerstruct. - In the message handling flow, likely in
protocol/v1/message.go.
“Please note that this is as per primary and limited understanding, any comments from status contributors are highly appreciated”
Outgoing Messages
-
Message Creation: When a user sends a message, it would likely be handled in the v1 protocol package.
-
Wrapping for Reliability: Before encryption, the message would be passed to the ReliabilityManager:
wrappedMessage, err := m.reliabilityManager.WrapOutgoingMessage(message.Payload, message.ChatID) -
Encryption: The wrapped message would then be encrypted using the existing encryption protocol, likely in the
EncryptionLayerstruct:m.EncryptionLayer.Payload = encryptedWrappedMessage -
Sending: The encrypted message is sent using the existing transport layer, possibly through the
TransportLayerstruct.
Incoming Messages
-
Message Reception: Incoming messages are likely received in the
HandleTransportLayermethod of theStatusMessagestruct. -
Decryption: The message would be decrypted in the
HandleEncryptionLayermethod. -
Unwrapping for Reliability: After decryption, the message is passed to the ReliabilityManager:
unwrappedMessage, missingDeps, err := m.reliabilityManager.UnwrapReceivedMessage(m.EncryptionLayer.Payload) -
Dependency Handling: If there are missing dependencies, the application would need to check its local history or retrieve them from a store:
if len(missingDeps) > 0 { foundDeps := m.checkLocalHistory(missingDeps) m.reliabilityManager.MarkDependenciesMet(foundDeps) remainingDeps := m.getRemainingDeps(missingDeps, foundDeps) if len(remainingDeps) > 0 { err := m.retrieveMissingMessages(remainingDeps) // Handle any error or retry } } -
Message Processing: The message can be shown to the end user on the UI as soon as it arrives, but with an indication such as “possible messages missing prior to this one”. The number of missing messages can be specified based on the number of unmet causal dependencies. Once a message is marked as having all dependencies met (i.e., “processed”), the message would be processed in the
HandleApplicationLayermethod and UI can remove the missing messages display.
Acknowledgment Handling
Marking Messages as Sent: The application would receive signals from the ReliabilityManager when outgoing messages are acknowledged:
m.reliabilityManager.SetMessageSentCallback(func(messageID string) {
m.markMessageAsSent(messageID)
})
Periodic Sync
-
Sync Signal: The ReliabilityManager would periodically signal the need for synchronization:
m.reliabilityManager.SetPeriodicSyncCallback(func() { m.initiateSync() }) -
Sync Process: The application would implement the
initiateSyncfunction to handle the actual synchronization process, by sending an empty sync message.
Next Steps
- Detailed technical specification of the library’s API
- Finalized integration plan with existing status-go message handling flow
- Prototype implementation focusing on core functionality
We look forward to your thoughts and feedback on this proposal !
{kind=link}