This is a recap on where we started, where we are now, some decisions we are making and how we plan to reduce risks and cut scope around the project.
Raw doc which was discussed on Monday and More extensive meeting notes.
tldr summary:
- Evaluation: Met secondary and teritary goals, but not primary goal yet.
- Decision: Extending Waku as a swarm for two weeks to validate model with simulation and do initial client integration, then handover to Core with retainer.
- Comment: See below for more details, as there are some risks w.r.t. v1, core integration unknowns and holidays.
- Decision: Removing optional/risky stuff from must-have/critical path: dns discovery / nim client / capabilities.
- Decision: Simulation ongoing, as it helps derisk project and validate approach, but not blocking critical integration path.
- Risk: not solving problem, mitigating with parallel track of simulation. Complemented with E2E testing within core.
- Risk: V1 timeline, QA resources and people availability. Handover to Core to ensure globally prioritized within context of V1. Rest of team on retainer if need be. Core needs to prepare handover if things aren’t finished before Adam and Andrea go on vacation.
Waku - Recap, evaluation and derisking
Evaluating the current state of Waku project, with respect to timeline and risks. Inspired by “Shape up” style project risk Shape Up: Stop Running in Circles and Ship Work that Matters. Decision points for cutting scope and isolating unknowns.
Context
Initial goals
When kicking off Waku in the middle of November last year, these were the specified project goals (Waku project and progress):
Project goals
- The primary goal is to fix the immediate bandwidth scalability issues with Whisper. See Fixing Whisper for great profit for background and rationale.
Secondary goals are:
- Ensure our already forked version of Whisper is documented enough to allow others to use the protocol, most immediately status-nim. Aside from new waku mode node modifications, this includes existing light node modifications, mailserver protocol, and additional packet codes.
- Increased ownership of our own existing protocol stack for Core, with iterative improvements and allowing for protocol upgrades. This includes future iterative improvements such as moving to libp2p, accounting for resources, settlement, alternative spam resistance solutions (zkSNARKs?), alternative routing (pss?), remote log usage, etc. If we do this right, culturally moving from waku/0 to waku/1/2/3 will be more efficient than trying to get whisper/v7 EIP accepted.
Teritiary goals are:
- Improve our way of working together and increase accountability, with a more focused group of stakeholders, closer-to-implementation research and research sprints.
Risk and timeline
Timeline was specified as getting Waku in a state where it is ready for the Status app within 6 weeks.
We identified a risk in availability with respect to v1 and other projects.
Briefly on current state
In terms of meeting our goals:
Outcome:
Consensus on: yes, no, no, no
By default, since six weeks have passed, this project should be killed. Why? Our risk appetite was set as a six week bet. Now, I don’t think people agree with this, but this should be an explicit decision with clear rationale.
Decision point: Extend project for 2 weeks?
Here’s what we want:
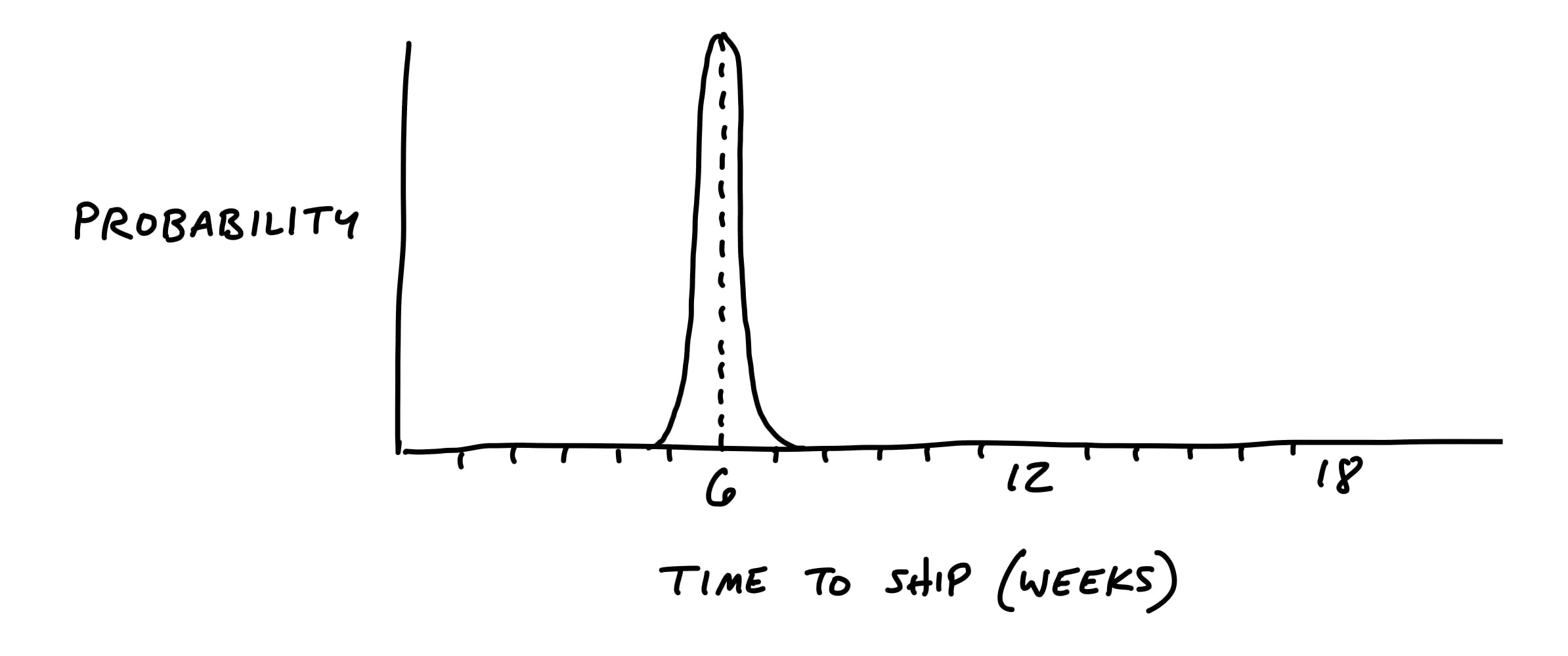
Here’s what we want to avoid:
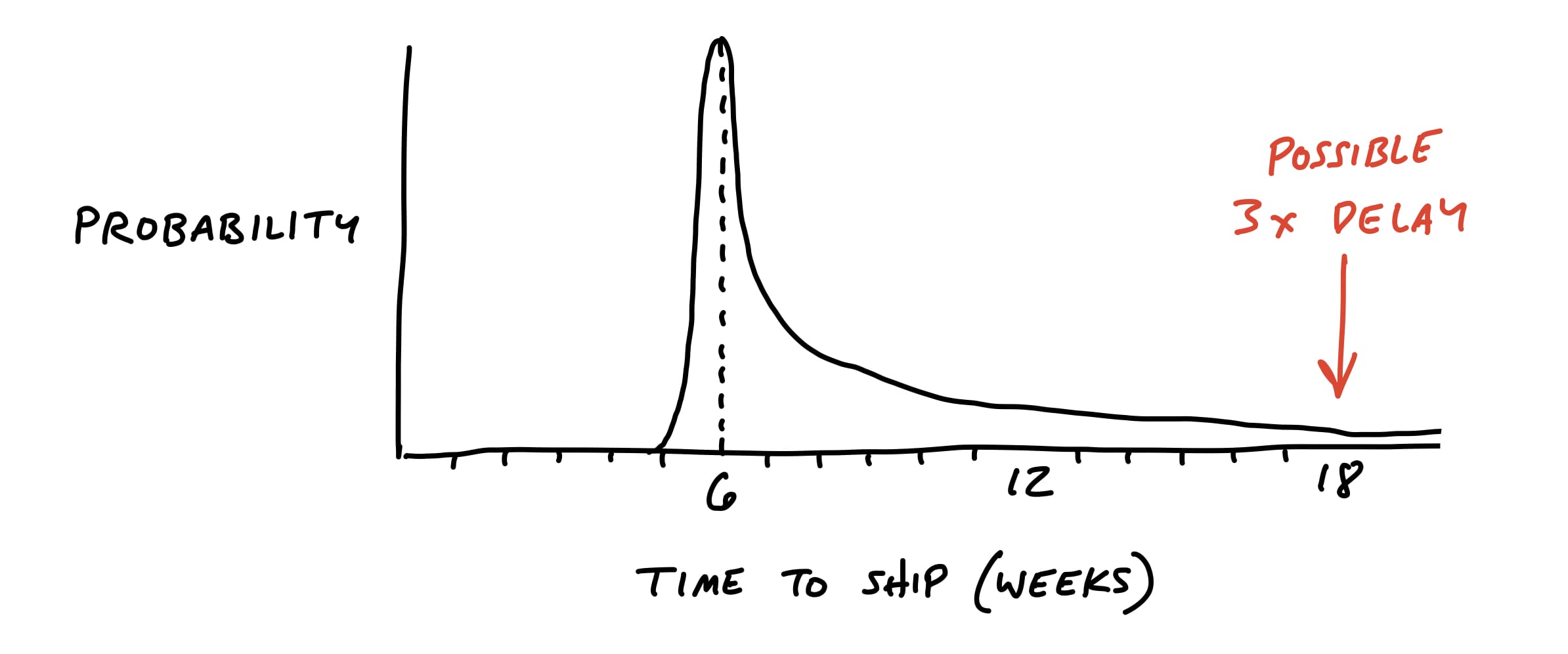
Rationale for extension:
- The primary must-have goal of BW reduction hasn’t been solved
- In this must-have tight scope, all tasks are (or should be) downhill. That is, it is mostly a question of execution, not open ended problems.
- We can achieve the above within a limited time period.
Outcome:
Everyone agreed on extending the project. The main source of contention was timeline. Core felt that two weeks was too optimistic, and that it depends on how we want to define done here. There is also concern over v1 task availability, QA resources as well as upcoming holidays which will necessiate handover (surfaced later). There seemed to be rough consensus on the following two tracks and handover:
-
Validate / try to falsify the model in a (primarily, initially Nim-only) based simulation within two weeks.
-
Core: Get client done and spec compliant. Get the end to end solution ready-ish to be tested in the app, but further debugging and testing will take longer and happen within the context of core, depending on v1 and Core resources/prioritization. This is partly pending depending on v1 timeline and QA resources.
-
Handover to Core and let additional Waku implementation be owned by Core - as that’s where the locus of control and global prioritization happens - unless flaws in the spec or model are discovered, in which case everyone else (Oskar/Dean/Kim) are available on a retainer.
Culling scope
- What things are absolutely must-haves vs nice-to-haves in terms of meeting our primary goal?
General question. Be critical. We want to make sure we compare with current baseline, which is the existing app, not some idea.
- Decision: DNS based discovery as part of initial release?
Outcome:
- Super valuable and needed, in general
- Not strictly necessary for initial release to solve BW problem
- Continue research and aim to get it in as soon as possible
- For initial release, use embedded static node list
- Good candidate for a separate “bet” after Waku
- Decision: Capabilities as part of initial release?
Outcome:
- Similar to above (this refers to beyond what is in the current spec)
- Decision: Use status-go for initial release?
Outcome:
- going with status-go - safer, audited, etc
- status-nim not well tested, separate bet
- Decision: Simulation as part of initial release?
Outcome:
- very desirable, additional complemented with in-app consumption measurement (core)
- not strictly necessary for integration (and we do have a model), but it helps reduce risk and model error
- continue as parallel track and timebox it, don’t block critical deployment track
- Sketch of must-have (WIP):
Source of truth is https://github.com/orgs/vacp2p/projects/2, to be updated this week in more detail
Outcome:
Consensus that this captures it, but list needs more detail.
- status-go client implement spec (Adam): Waku 0: integrate Waku node and Waku client · Issue #1683 · status-im/status-go · GitHub
- deployment to cluster (Adam/Jakub): https://github.com/vacp2p/pm/issues/4
- app integration (Andrea): Improve bandwidth usage · Issue #9465 · status-im/status-mobile · GitHub
separate:
- simulation (Kim) Basic Waku simulation · Issue #1 · vacp2p/simulations · GitHub
- Any other decisions we should make?
Outcome:
No.
Outstanding risks
We also discussed various risks and how to mitigate them, only partial notes here.
-
General questions: Any technical risks we are missing? Design wise? Interdependencies?
-
Risk: Not actual solving the problem
- Mitigation: simulation work (Kim)
- QA/e2e testing throuh Core
- Risk: Bridging/compatibility fuck up - bridging doesn’t work, compatibility between v0 and v1
- Bridging clear spec-wise and in status-nim, need to figure out on status-go side. As long as envelopes are same should be OK.
- Risk: Deployment - mailserver state, actual 1.1 release and people upgrading, also see compatibility above
- Largely Core concern, nothing specific to note here.
- Risk: People availability - v1 core obligations, other projects, (holiday?)?
- Specifically Andrea and Adam wrt v1 and Kim wrt eth1 - 2 weeks commitment?
- Adam mostly on Waku with some v1 stuff, Andrea largely on v1 stuff, Kim on simulation
- Adam going on vacation in 2w, Andrea vacation after v1
- Discussion regarding people and handover, but this is a risk from a core implementation POV
- v1 and QA in general (see Core handover decision about)
- Too much work on go client, additional help needed?
- possibly Pedro, Adam will ask if need
- Risk: Core integration / build risk?
- Client compatibility? (see above)
- Core integration unknowns?
- Build risks?
- Deployment with static list, which nodes, how deal with more nodes being deployed?
(mitigated by DNS, good rationale for it being next 2w-6w bet) - Connectivity issue: logic for 1 node vs 2 node connection?
- check whether infra is resilient before going live, more than one connection at start
- Risks: Misc
- Update partition topic? (later)
- 100x traffic, node list?
- Other interdependencies not captured?
- Unknown unknowns and other risks not mentioned? Be critical!
Nothing mentioned.
If I missed or misrepresented anything, please write here!