Setting clear and relevant metrics for a decentralized product is challenging because it’s difficult or impossible to know what happens on the user’s device. To gain some insight, we are using telemetry, but this has limitations.
After reviewing with Insights, the preferred method for confirming the functional behavior of a given protocol and implementation under real conditions remains large-scale simulations and stress testing.
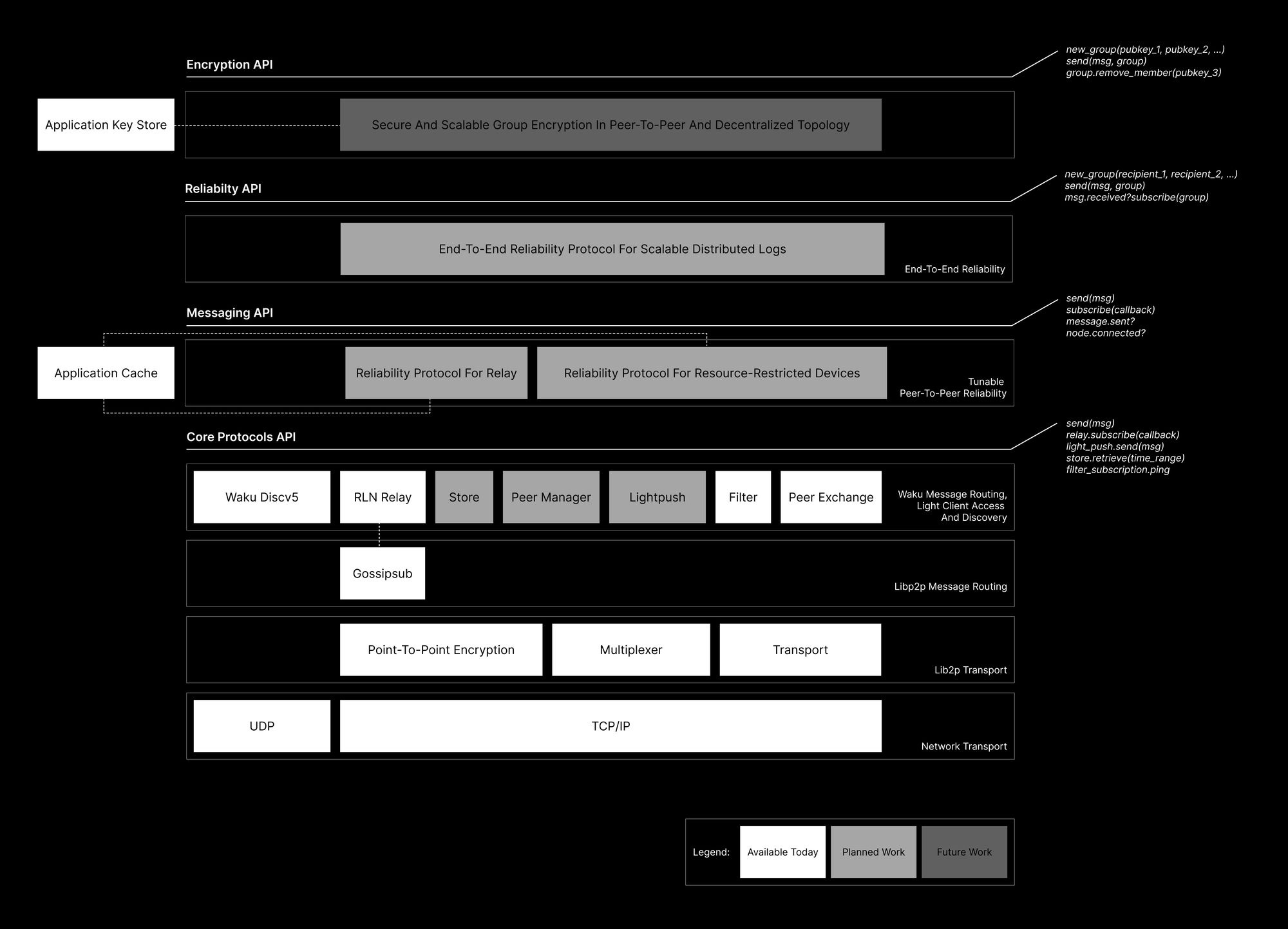
Using this stack overview from https://blog.waku.org/2024-06-20-message-reliability/ for terminology:
{kind=link}
Core Protocols API are being stress tested by the Vac-DST team, as per their waku commitments.
- Regression testing is performed at every nwaku release.
- Req-res protocol work (store, light, filter) is still work in progress (afaik).
The bulk of 2024 Waku milestones focuses on Status app message reliability, also known as “messaging API”. These have been implemented in status-go and are being moved to go-waku.
The Vac-QA team has done an excellent job testing those protocols from a higher layer (Chat protocol), in networks with packet drop and latency.
However, we still need stress testing to confirm the protocols behave as expected at scale.
Stress Testing Messaging API
The question is, how do we get this done?
There are two strategies:
A. Ensure that reliability protocols for relay and resource-restricted clients are fully migrated to go-waku and proceed with stress testing go-waku nodes.
B. Wait until those protocols are migrated in nwaku, and used in Status Desktop, and then proceed to the stress testing.
In both cases, it means exposing those protocols to the node’s REST API.
The final goal is for nwaku’s REST API and FFI API to be closely related, and to include those new protocols. But this is unlikely to be delivered before mid-2025.
Stress Testing as a Metric
Stress testing is likely to be the best metric we have to confirm the efficacy of our work and that protocols and implementation behave as promised; so that applications can rely on them.
However, for stress testing to be a metric that measures the success of a milestone, the time gap between software delivery and stress testing run needs to be timely and minimal. So that a project team delivering a milestone, can get early enough feedback on whether metrics criteria are fulfilled, and proceed to correction before moving to production.
Considering the backlog DST is working with, the question is whether this is an achievable task and whether projects can use simulation reports as milestone metrics.