We receive messages in Status desktop via two Waku protocols: Relay or Store. None of them offers 100% reliability, Store might be a bit more reliable since those nodes are generally high availability nodes and therefore more likely to receive the Relay messages.
We have other protocols on top of those to ensure E2E deliverability of messages,
- MVDS: the receiver doesn’t know if we are missing messages, the sender will resend if no acknowledgement was received.
- New E2E protocol: the receiver might become aware that some messages are missed based on causal histories and bloom filters.
Connection management
Status Desktop will have connections to peers for each pubsub topic, if I start status connected to 3 pubsub topics then I’ll need to connect to peers for those topics, Status will check every 15 seconds those connections and update its connection status per topic.
See the following table as an example of peer connection health status:
| pubsub topic | number of connected peers | connection status |
|---|---|---|
/waku/2/rs/16/32 |
0 | UnHealthy |
/waku/2/rs/16/64 |
3 (less than D=4) | MinimallyHealthy |
/waku/2/rs/16/128 |
4 (at least D=4) | SufficientlyHealthy |
Status Desktop most likely won’t have high availability, it might be running on a laptop connected to unreliable networks, might get wifi disconnects or laptop might go to sleep or hibernate, etc. All those problems could be reduced to the following two main issues that Status needs to handle:
- Offline: no peers connected on a pubsub topic, either because we don’t have other peers in this pubsubtopic or because we don’t have connection ourselves. In the case of no connection ourselves two things can happen:
- We don’t know we are offline. We have observed that if the disconnection is less than 25-30 seconds Status won’t notice this, since we ping peers every 15 seconds plus the timeout.
- We know we are offline. After those 25 seconds the ping will fail and Status will notice the disconnection.
- Computer Sleep/Hibernate: Again, currently we might not notice if the app is suspended by 25 seconds, more time will get noticed.
In either case we have the issue of not noticing if we are offline or sleep for short spans of 30 seconds BUT if the span is larger than 30 seconds we will notice and therefore we can request that time range using Store. The problem remains for the small 30 second periods that might become quite common for a laptop.
Possible solutions
In the following picture we see at connection states for the app and how it receives the messages (blue: Store, green: Relay). when we are online (i.e.: minimally connected to peers for the pubsub topic), we are getting the messages realtime via Relay, for the periods that we are offline we are not receiving messages at all (obviously), but when we detect that we are back online we do a Store query for the time that we know we were offline. See the diagram below:

This would be great BUT we have those 30 second spans that we cannot detect if we were offline, therefore we would be missing those messages.
The reality would look more like the following and maybe it is good enough solution.
Maybe good enough
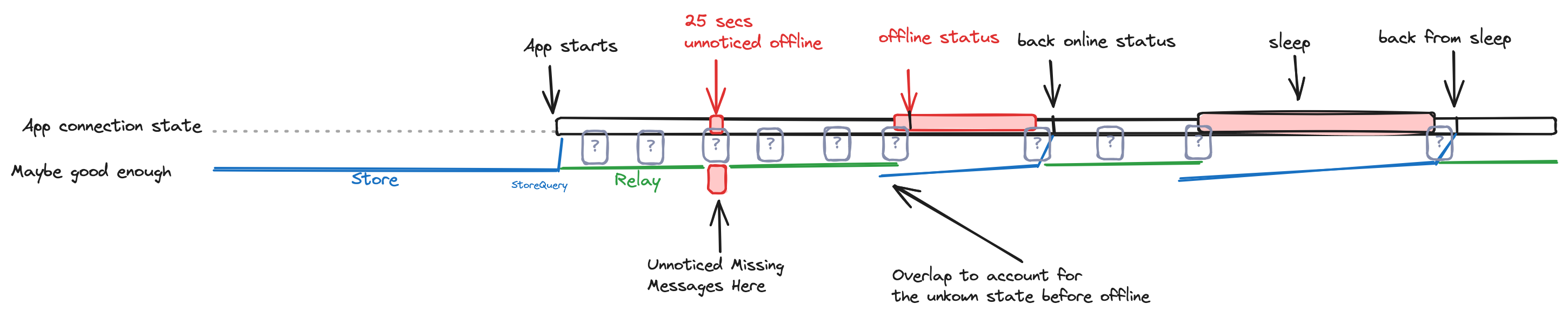
This figure adds grey question marks for those 30 second periods that we don’t know if we are actually offline, if we are actually offline then we will miss Relay messages if they happen to be sent on those times and we wouldn’t request them with Store.
In this scenario, can MVDS or the new E2E protocol help? Yes, MVDS will retry the send, if at the moment of the retry we are online we could get it by Relay, if we are offline (and we know it) then we would receive it via Store when we go back online. The problem is that we might get it later than expected. And still we might miss some messages not using other reliability protocols.
Periodic-store approach (aka: Schwarzenegger approach)

The way to maximise receiving messages is using Store all the time (e.g.: request messages periodically every 1 minute), together with Relay for real-time receives. I’m unsure how this would compare to just using Filter at least from the receiving messages point of view.
This approach is merged in master and will be used in Desktop shortly. Obvious problem is that it will be very chatty with store nodes but it will sort out the issue of not receiving messages during small 30 second offline periods.
Any comments are welcome.